- Tue 25 September 2018
- Publication
Feedback Control for Cassie with Deep Reinforcement Learning
Zhaoming Xie, Glen Berseth, Patrick Clary, Jonathan Hurst, Michiel van de Panne
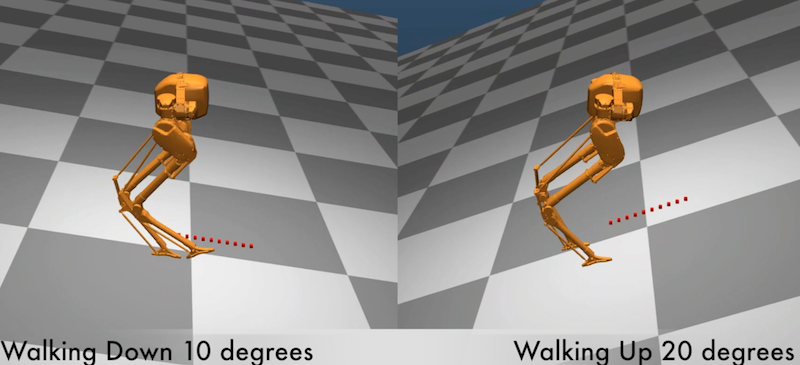
Deep reinforcement learning has achieved great strides in solving challenging motion control tasks. Recently, there has been significant work on methods for exploiting the data gathered during training, but there has been less work on how to best generate the data to learn from. For continuous action domains, the most common method for generating exploratory actions involves sampling from a Gaussian distribution centred around the mean action output by a policy. Although these methods can be quite capable, they do not scale well with the dimensionality of the action space, and can be dangerous to apply on hardware. We consider learning a forward dynamics model to predict the result, \((x_{t+1})\), of taking a particular action, \((u_{t})\), given a specific observation of the state, \((x_{t})\). With this model we perform internal look-ahead predictions of outcomes and seek actions we believe have a reasonable chance of success. This method alters the exploratory action space, thereby increasing learning speed and enables higher quality solutions to difficult problems, such as robotic locomotion and juggling