- Thu 13 August 2020
- Publication
- John D. Co-Reyes, Suvansh Sanjeev, Glen Berseth, Abhishek Gupta, Sergey Levine
- #ReinforcementLearning
John D. Co-Reyes, Suvansh Sanjeev, Glen Berseth, Abhishek Gupta, Sergey Levine
UC Berkeley
Much of the current work on reinforcement learning studies episodic settings, where the agent is reset between trials to an initial state distribution, often with well-shaped reward functions. Non-episodic settings, where the agent must learn through continuous interaction with the world without resets, and where the agent receives only delayed and sparse reward signals, is substantially more difficult, but arguably more realistic since real-world environments do not present the learner with a convenient "reset mechanism" and easy reward shaping. In this paper, instead of studying algorithmic improvements that can address such non-episodic and sparse reward settings, we instead study the kinds of environment properties that can make learning under such conditions easier. Understanding how properties of the environment impact the performance of reinforcement learning agents can help us to structure our tasks in ways that make learning tractable. We first discuss what we term "environment shaping" -- modifications to the environment that provide an alternative to reward shaping, and may be easier to implement. We then discuss an even simpler property that we refer to as "dynamism," which describes the degree to which the environment changes independent of the agent's actions and can be measured by environment transition entropy. Surprisingly, we find that even this property can substantially alleviate the challenges associated with non-episodic RL in sparse reward settings. We provide an empirical evaluation on a set of new tasks focused on non-episodic learning with sparse rewards. Through this study, we hope to shift the focus of the community towards analyzing how properties of the environment can affect learning and the ultimate type of behavior that is learned via RL.
Motivation
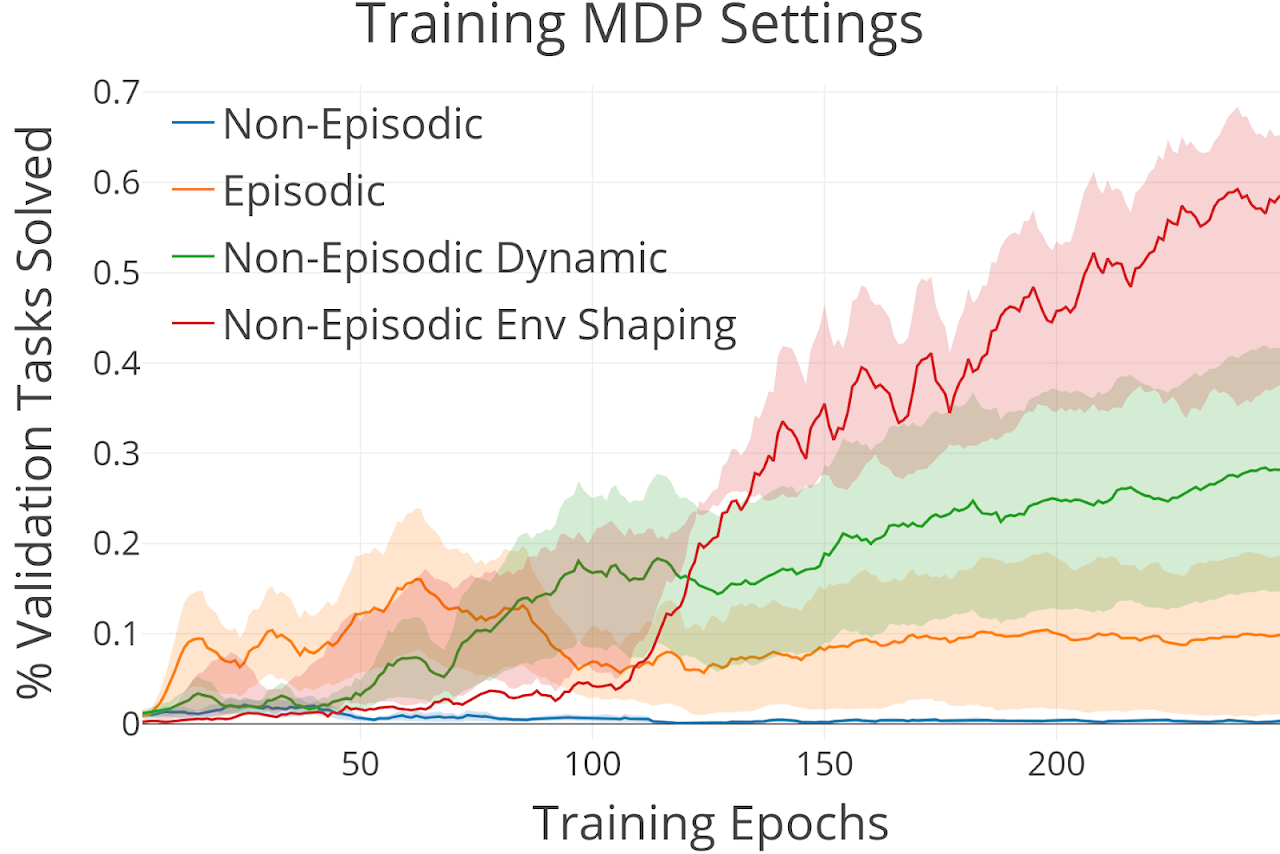
Reinforcement learning is normally studied in the episodic setting where the agent is reset each episode. This makes learning easier but in the real world, we would like our agent to continually learn with minimal human supervision and without having to manually reset the agent each time it makes a mistake. Reset-free or non-episodic learning is difficult, especially with sparse reward where the agent may never experience any rewarding states and not make any progress. Without any algorithmic changes however, certain properties of the environment can make learning without resets and with sparse reward more tractable. We investigate and analyze these properties: environment shaping and environment dynamism.
Evnvironent Properties
We study a set of properties often overlooked when considering how to develop RL algorithms.
Environment Shaping
alters the initial state or dynamics of the non-episodic training MDP to make learning more tractable compared to an unshaped environment. For example if the agent is tasked with eating apples a shaped environment may initially contain an abundance of easily obtainable apples that allows the agent to learn that apples are rewarding. As the easily obtainable apples are consumed, the agent must eventually learn to reach apples that are further away and take more steps to reach such as climbing a ladder up a tree. A shaped environment can be thought of as a natural curriculum for the non-episodic setting.
Environment Dynamism
refers to the MDP transition entropy regardless of the agent's actions and provides a soft uniform reset mechanism for the agent, helping it reach a wider variety of states in the non-episodic setting. A static environment might correspond to a very controlled setting where no other entity or part of the environment changes on its own while a dynamic environment would involve the opposite of this. Dynamics environments can be found readily in the real world (humans and other agents provide natural dynamism) and so we may just need to deploy our agents in these existing settings.

This post is based on the following paper:
- John D. Co-Reyes, Suvansh Sanjeev, Glen Berseth, Abhishek Gupta, Sergey Levine
Ecological Reinforcement Learning
Project Website