- Sun 08 November 2020
- Publication
- 2021 IEEE International Conference on Robotics and Automation (ICRA)
DisCo RL: Distribution-Conditioned Reinforcement Learning for General-Purpose Policies
Soroush Nasiriany, Vitchyr Pong, Ashvin Nair, Khazatsky Alexander, Glen Berseth, Sergey Levine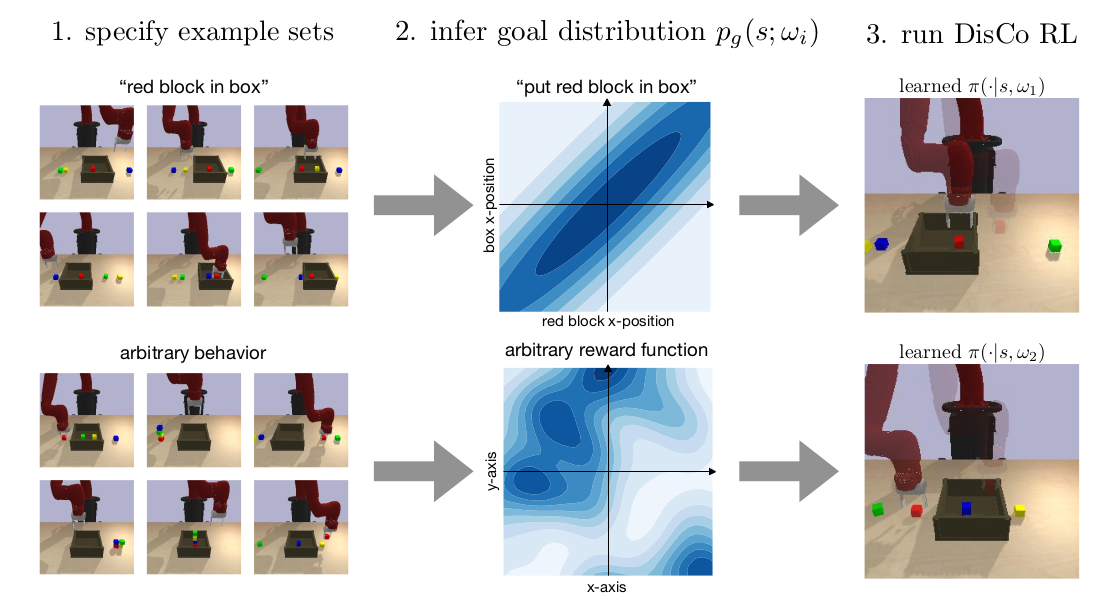
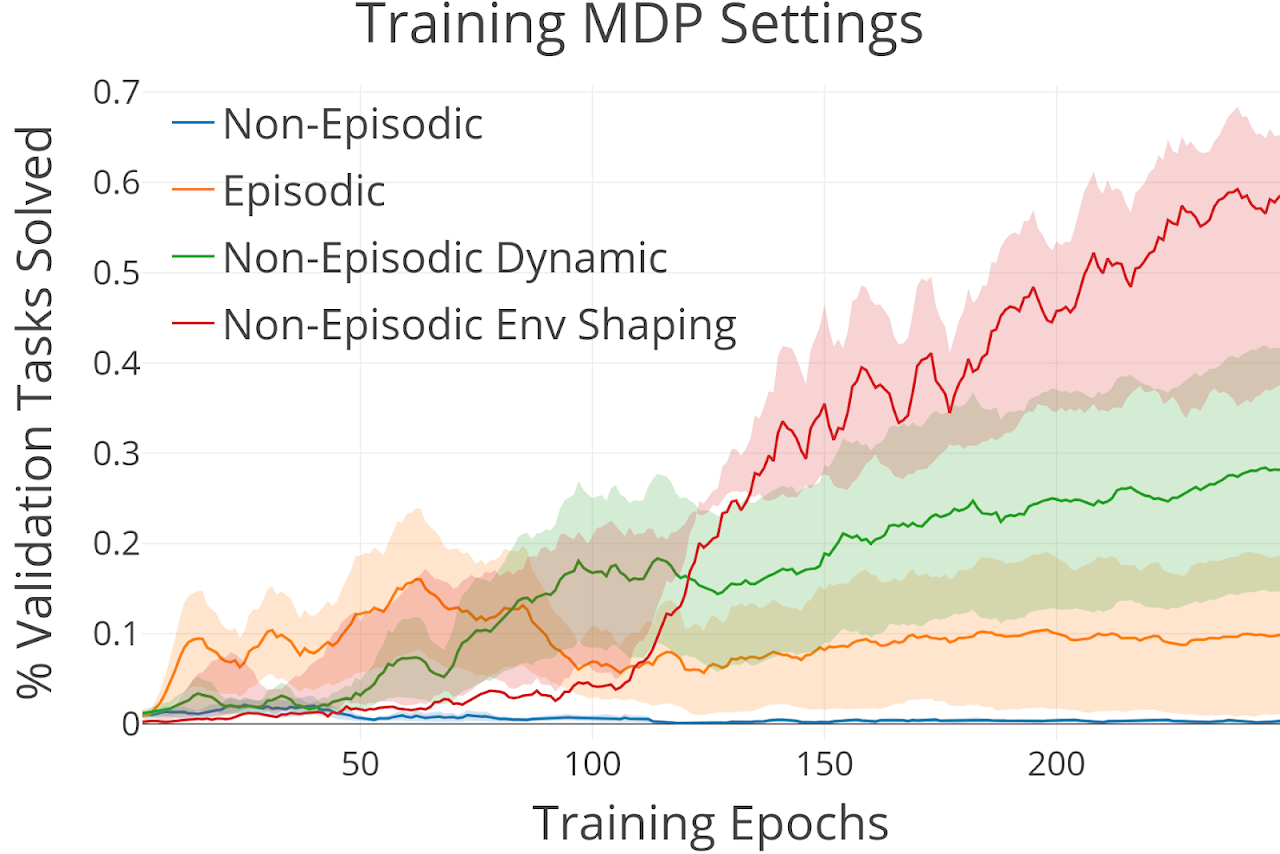
Can we use reinforcement learning to learn general-purpose policies that can perform a wide range of different tasks, resulting in flexible and reusable skills? Contextual policies provide this capability in principle, but the representation of the context determines the degree of generalization and expressivity. Categorical contexts preclude generalization to entirely new tasks. Goal-conditioned policies may enable some generalization, but cannot capture all tasks that might be desired. In this paper, we propose goal distributions as a general and broadly applicable task representation suitable for contextual policies. Goal distributions are general in the sense that they can represent any state-based reward function when equipped with an appropriate distribution class, while the particular choice of distribution class allows us to trade off expressivity and learnability. We develop an off-policy algorithm called distribution-conditioned reinforcement learnin (DisCo) to efficiently learn these policies. We evaluate DisCo on a variety of robot manipulation tasks and find that it significantly outperforms prior methods on tasks that require generalization to new goal distributions.